AIクリエーターの道 ニュース:データ統合を革新!Azure ADFでメタデータ駆動型ETLフレームワークを構築し、データ処理を自動化、効率化。 #AzureADF #データ統合 #ETL
動画で解説
データ整理が劇的にラクになる?魔法の設計図「メタデータ」を使った最新データ活用術
こんにちは!AI技術解説ライターのジョンです。
皆さんの会社では、データはどこに保存されていますか?Excelファイル、社内のデータベース、Salesforceのようなクラウドサービス…。あちこちにデータが散らばっていて、「全部まとめて分析したいのに、準備が大変すぎる!」なんて悩みを抱えている方も多いのではないでしょうか。
これまでのやり方だと、新しいデータをつなぐたびに専門家が一つひとつ手作業で「データの道」を作っていました。これでは時間もコストもかかり、変化に対応するのがとても難しいんです。
でも、もし「一度作れば、あとは簡単な指示を変えるだけで、どんなデータでも自動で整理してくれる」そんな夢のような仕組みがあったらどうでしょう?
実は今、AIやクラウドの世界では、そんな賢いデータ活用の方法が注目されています。その鍵を握るのが「メタデータ駆動」という考え方。今回は、この新しいアプローチについて、料理にたとえながら、誰にでもわかるように解説していきますね!
「メタデータ駆動」ってなに?データ活用の新しいカタチ
まず、データ活用の基本に「ETL」というプロセスがあります。これは、データを「Extract(抽出)」し、「Transform(変換)」し、「Load(格納)」する、という一連の流れのこと。つまり、あちこちにある生データを、分析しやすいように綺麗に整えて、特定の場所に運ぶ作業を指します。
従来のやり方は、このETLのプロセスを、データの種類ごとにオーダーメイドで作っていました。これはまるで、特定の食材(データ)のためだけに、専用のキッチンと調理器具を毎回ゼロから用意するようなものです。新しい食材が増えるたびに、また新しいキッチンを作る…考えただけで大変ですよね。
そこで登場するのが「メタデータ駆動」というアプローチです。
「メタデータ」とは、一言でいうと「データに関するデータ」、つまり「指示書」や「設計図」のことです。どのデータを(どこから)、どのように加工して(どうやって)、どこに運ぶか(どこへ)といった情報がすべて書かれています。
このアプローチでは、まず柔軟で高性能な「巨大なセントラルキッチン」を一つだけ作ります。そして、新しいデータ(食材)を扱いたいときは、キッチンを作り直すのではなく、「レシピ(メタデータ)」を書き換えるだけで済ませるのです。これなら、新しい料理にどんどん対応できますよね!
この記事の元になった事例では、この「セントラルキッチン」の役割を、マイクロソフトが提供する「Azure Data Factory(ADF)」というクラウドサービスが担っています。
仕組みのキモは「設計図」と「専門ワーカー」
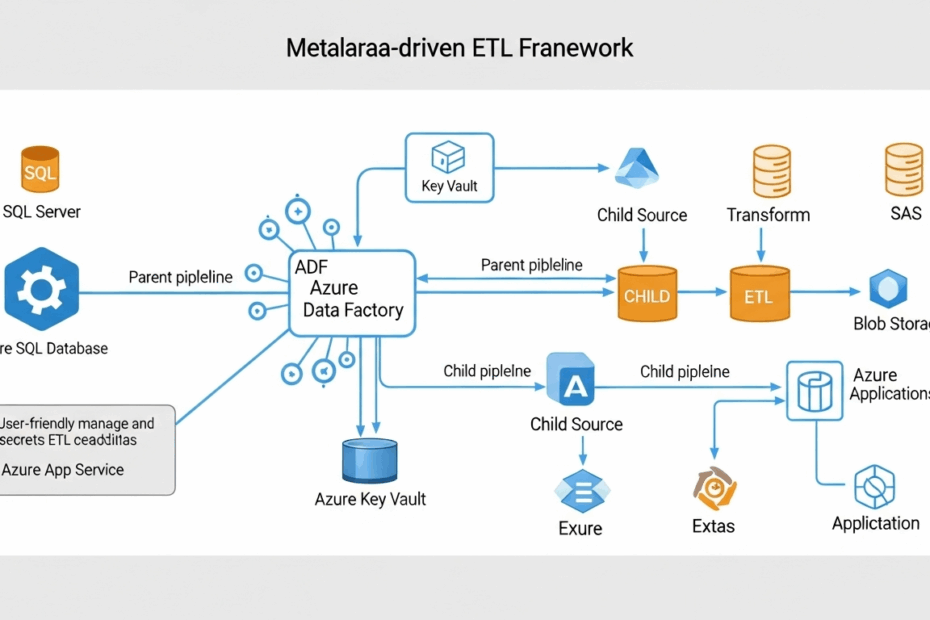
では、この「メタデータ駆動」の仕組みは、具体的にどうなっているのでしょうか。先ほどの料理のたとえで、その全体像を見てみましょう。
この仕組みは、主に3つの要素で構成されています。
- メタデータ(レシピ): どの食材(データ)を、どの倉庫(データベース)から持ってきて、どう調理(変換)し、どのお皿(保存先)に盛り付けるか、といった全ての指示が書かれたレシピです。このレシピは、Azure SQL Databaseというデータベース(レシピ帳)に保管されます。
- 親パイプライン(ヘッドシェフ): レシピを読んで、全体の流れを指揮する総監督、つまり「ヘッドシェフ」です。ヘッドシェフ自身は調理しません。レシピを見て、「この作業はAさん、あの作業はBさんにお願いしよう」と、各専門のシェフに指示を出すのが仕事です。
- 子パイプライン(専門シェフ): ヘッドシェフから指示を受けて、実際の作業を行う「専門シェフ」たちです。「野菜を切る専門家」「肉を焼く専門家」「盛り付けの専門家」のように、それぞれが得意な作業を持っています。例えば、「データベースからデータベースへデータを移す」専門シェフや、「ファイルからデータを読み取る」専門シェフがいる、というイメージです。
この仕組みの素晴らしい点は、新しいデータ連携が必要になったとき、私たちは「レシピ(メタデータ)」を更新するだけで良い、というところです。ヘッドシェフと専門シェフたちは、新しいレシピを渡されれば、その通りに動いてくれるので、キッチン自体を改装する必要は一切ありません。これが、柔軟で効率的なデータ連携を実現する秘密なのです。
システムを支える、その他の重要な役割
この「セントラルキッチン」をスムーズに運営するためには、他にもいくつか重要な仕組みがあります。
セキュリティ(金庫番)
データベースのパスワードのような機密情報は、レシピに直接書き込むわけにはいきません。そこで、「Azure Key Vault」という鍵付きのデジタル金庫を使います。レシピには「金庫の鍵」の場所が書かれているだけで、実際のパスワードは金庫の中に安全に保管されるため、セキュリティも万全です。
柔軟な実行(営業時間の調整)
このキッチンは、様々なタイミングで稼働させることができます。
- 毎日決まった時間に動かす「定時実行(スケジュール実行)」
- 必要なときにボタン一つで動かす「オンデマンド実行」
- 新しい食材が届いたら自動で調理を始める「イベント実行」
このように、ビジネスの要求に合わせて柔軟に対応できるのです。
監視とログ(品質管理)
全ての調理工程は記録され、何か問題が起きたとき(例えば、調理に失敗したときなど)は、すぐにアラートが飛ぶようになっています。これにより、システムの安定稼働と高い品質を保つことができます。
簡単な操作画面(オーダーシステム)
さらに、専門家でなくても、簡単なWeb画面から「レシピ(メタデータ)」を追加したり変更したりできる仕組みも用意されています。これにより、現場の担当者が自分たちでスピーディにデータ連携を追加できるようになり、全体の効率がぐっと上がります。
筆者の感想
今回の元記事を読んで、僕が一番感じたのは「初めの設計が未来を楽にする」ということです。メタデータ駆動の仕組みは、最初にセントラルキッチン全体を設計する必要があるので、少し手間がかかるかもしれません。しかし、一度その土台をしっかり作ってしまえば、後からデータが増えたり、要件が変わったりしたときの対応が、驚くほど簡単かつスピーディになります。
これからの時代、データはますます増え、多様化していくでしょう。そんな中で、一つひとつ手作業で対応するのではなく、このような柔軟で拡張性の高い「仕組み」で対応するという考え方は、データ活用の世界で間違いなく主流になっていくと感じました。
この記事は、以下の元記事をもとに筆者の視点でまとめたものです:
Designing a metadata-driven ETL framework with Azure ADF: An
architectural perspective