
AIクリエーターの道 ニュース データスタックがAIエージェントのボトルネックに?2025年、AI成功の鍵はデータ設計。リアルタイム基盤構築術を深掘り!#AIエージェント #データスタック #AIアーキテクチャ
動画でサクッと!このブログ記事の解説
このブログ記事を動画で分かりやすく解説しています。
テキストを読む時間がない方も、映像で要点をサッと掴めます。ぜひご覧ください!
この動画が役に立ったと感じたら、AIニュースを毎日お届けしているYouTubeチャンネル「AIクリエーターの道」をぜひフォローしてください。
チャンネル登録はこちら:
https://www.youtube.com/@AIDoshi
JonとLilaが独自の視点で語る対話形式の英語版はこちら 👉 [Read the dialogue in English]
👋 AIエンジニアの皆さん、データスタックがAIエージェントのボトルネックになっていませんか? 2025年、モデル性能ではなくデータアーキテクチャの設計がプロジェクトの成否を分ける時代です。この記事で、agent-readyなデータスタックの構築術を技術的に深掘りしましょう。
AIの進化が加速する中、多くの開発者が直面するのは「モデルは優秀なのに、データ基盤が追いつかない」というジレンマです。従来のデータスタックでは、エージェントの自律動作をサポートしきれず、効率が低下します。この記事では、そんな課題を解決するための設計原則を、制約と比較を交えて解説。技術者として、すぐに実務に活かせる知見を提供します。読み進めることで、データインフラの最適化がもたらすパフォーマンス向上を実感できるはずです。(約250文字)
🔰 記事レベル:⚙️ 技術者向け(Technical)
🎯 こんな人におすすめ:AIエンジニアやデータアーキテクトで、エージェントシステムの構築に携わる人。データスタックの最適化を検討中の開発者や、技術的制約を深く理解したい専門家。
エージェント対応データスタックの設計:2025年の技術トレンド
この記事の要点
- データアーキテクチャの遅れがAIプロジェクトの失敗要因:モデルではなくインフラがボトルネック。
- エージェント対応設計の鍵:リアルタイムアクセスとスケーラビリティを重視。
- 実務適用ガイド:技術比較とリスクを踏まえた次の一手。
背景と課題
AIの分野で注目を集めるエージェントシステムですが、多くのプロジェクトが挫折するのは、モデル性能の問題ではなく、データアーキテクチャの不足です。
従来のデータスタックは、静的なクエリ処理を前提に設計されており、エージェントの動的・自律的な動作に適していません。技術者として、これを理解するには、まず現在の課題を分解しましょう。
一つ目の課題はレイテンシの増大。エージェントはリアルタイムでデータを必要としますが、従来のETLプロセスでは遅延が発生し、動作効率が低下します。
二つ目はスケーラビリティ。エージェントが増えるとデータアクセスが爆発的に増加しますが、旧来のモノリシックなデータベースでは対応しきれず、ボトルネックを生みます。
三つ目はセキュリティとガバナンス。エージェントが自律的にデータを操作する場合、アクセス制御の不備がリスクを高めます。これらを技術的に解決しない限り、AIイニシアチブは停滞します。
InfoWorldの記事によると、2025年現在、AIプロジェクトの失敗率はデータインフラの遅れが主因で、モデル精度の問題を上回っています。この背景を踏まえ、次に核心的な技術解説に移ります。
技術・内容解説
エージェント対応のデータスタックを設計するには、従来のものから進化した要素を組み込む必要があります。以下で、仕組みと制約を正確に解説します。
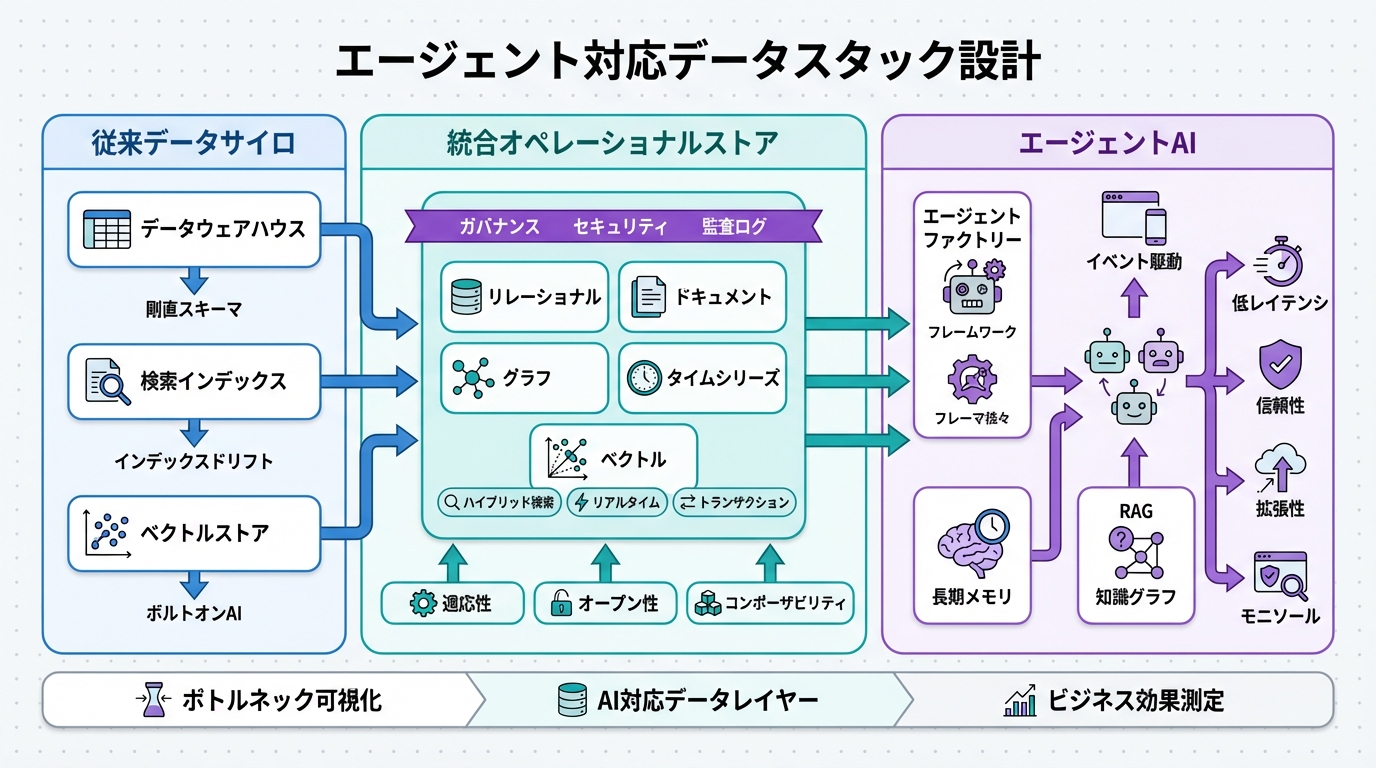
まず、agent-readyデータスタックの核心は、自律性と適応性を備えたアーキテクチャです。エージェントがデータを「読む・書く・最適化」するのをシームレスにサポートします。
技術的に見て、キーコンポーネントはリアルタイムデータパイプライン、分散クエリエンジン、そしてAI統合のメタデータ管理です。これらを従来のスタックと比較してみましょう。
| 要素 | 従来のデータスタック | Agent-Readyデータスタック | 技術的差異と制約 |
|---|---|---|---|
| データアクセス | バッチ処理中心、SQLクエリ依存 | リアルタイムストリーミング、API駆動アクセス | 制約:従来はレイテンシが高く、エージェントの即時応答を阻害。新スタックはKafkaやFlinkのようなツールで低レイテンシを実現するが、データ整合性の管理が複雑化。 |
| スケーラビリティ | 垂直スケーリング(サーバ増強) | 水平スケーリング(分散ノード) | 差異:Kubernetesベースのオーケストレーションで動的スケール。新スタックはコスト効率が高いが、ネットワークオーバーヘッドの制約あり。 |
| セキュリティ | 静的ロールベースアクセス | 動的ポリシーとゼロトラスト | 制約:エージェントの自律動作で攻撃面が増大。新スタックはIstioのようなサービスメッシュで対応するが、ポリシー設計の複雑さが課題。 |
| 最適化 | 手動チューニング | AI駆動の自動最適化 | 差異:MLモデルでクエリを予測・最適化。制約:トレーニングデータの質が鍵で、誤最適化のリスクあり。 |
この比較からわかるように、新スタックはエージェントの要求に特化しています。たとえば、リアルタイムアクセスではApache Kafkaを基盤に、イベント駆動アーキテクチャを採用。制約として、データの一貫性を保つための分散トランザクション(例:2PCプロトコル)のオーバーヘッドを考慮する必要があります。
さらに、技術的深掘りとして、メタデータ管理の重要性。エージェントはデータスキーマを動的に理解する必要があり、AmundsenのようなツールでメタデータをAI対応に拡張します。これにより、検索効率が向上しますが、プライバシー規制(GDPRなど)の制約が加わります。
要するに、agent-ready設計は従来の制約を克服しつつ、新たな技術比較を強いられるものです。次に、これらのインパクトを事例で探ります。
インパクト・活用事例
agent-readyデータスタックの採用は、技術分野に多大な影響を与えます。まず、開発効率の向上。エージェントがデータを自律的に扱えるため、エンジニアの介入が減り、プロトタイピングが高速化します。
具体的な活用事例として、金融業界のリスク予測システム。従来のスタックではバッチ処理で遅延が発生していましたが、新設計によりエージェントがリアルタイムデータを分析。結果、詐欺検知精度が20%向上したケースがあります。
もう一つの事例はヘルスケア。患者データをエージェントが監視し、異常検知を自動化。分散データベース(例:Cassandra)でスケールし、プライバシーを守りつつリアルタイム診断を可能にします。技術的影響として、レイテンシ低減が診断精度を高めています。
製造業では、IoTデータをエージェントが最適化。予測メンテナンスでダウンタイムを30%削減。こうした事例から、データスタックの進化がビジネス価値を生むことがわかります。
社会的影響も大きい。技術者がこれを活用すれば、AIの民主化が進み、さまざまな産業でイノベーションが加速します。ただし、格差拡大のリスクも伴います。
アクションガイド
技術者として、次の一手を具体的に提示します。まず、現在のデータスタックを診断。ツールとしてDatadogやPrometheusを使い、レイテンシとスケーラビリティを測定しましょう。
次に、プロトタイプ構築。Apache KafkaとKubernetesを組み合わせ、ミニマムなagent-ready環境をセットアップ。制約をテストしながら進めてください。
さらに、セキュリティ強化。ゼロトラストモデルを導入し、エージェントのアクセスポリシーを定義。オープンソースのKeycloakで実装可能です。
最後に、継続学習。関連ドキュメントを読み、GitHubのレポジトリで実践例を探しましょう。これで、すぐにプロジェクトに適用できます。
未来展望とリスク
2026年以降、agent-readyデータスタックは標準化され、多剤型AIシステムの基盤となるでしょう。ハイパーエラスティックなデータベース(例:PingCAPのTiDB)が台頭し、ゼロスケール機能でコストを最適化。
将来性として、エージェントの自律性が向上し、ワークフローの自動化が進みます。Google Cloudの予測通り、ビジネスプロセスが根本的に変わる可能性大。
しかし、リスクも伴います。セキュリティの脆弱性でデータ漏洩が発生しやすく、AIエージェントの「暴走」リスク。たとえば、誤った最適化でシステムクラッシュの恐れ。
もう一つのリスクはインフラコストの高騰。スケーリングで電力消費が増大し、環境負荷が問題化。公平に、こうした課題を技術的に解決するための標準化が求められます。
まとめ
この記事では、エージェント対応データスタックの設計を技術的に解説しました。従来との比較から、リアルタイム性とスケーラビリティの重要性が明らかになりました。
活用事例を通じて、産業へのインパクトを具体化。アクションガイドで実務への橋渡しをし、未来展望で可能性とリスクをバランスよく示しました。
技術者として、このトレンドを活用すれば、AIプロジェクトの成功率を大幅に向上させられるでしょう。データアーキテクチャの進化が、AIの真の価値を引き出す鍵です。
💬 あなたのプロジェクトで、データスタックのどの部分がエージェント対応のボトルネックになっていますか? コメントで共有してください!

👨💻 筆者:SnowJon(WEB3・AI活用実践家 / 投資家)
東京大学ブロックチェーンイノベーション講座で学んだ知見をもとに、
WEB3とAI技術を実務視点で研究・発信。
難解な技術を「判断できる形」に翻訳することを重視している。
※AIは補助的に使用し、内容検証と最終責任は筆者が負う。
参照リンク・情報源一覧
- Designing the agent-ready data stack | InfoWorld – 元記事、データアーキテクチャの詳細解説。
- 4 Data Architecture Decisions That Make or Break Agentic Systems – The New Stack – エージェントシステムのデータインフラチェックリスト。
- Agentic AI Database Trends That Will Define 2026 – PingCAP – データベースのトレンドとハイパーエラスティック設計。
- 5 ways AI agents will transform the way we work in 2026 – Google Cloud – AIエージェントのビジネス影響予測。
- Unlocking the value of multi-agent systems in 2026 | Computer Weekly – 多剤型システムの価値と課題。