
GPUを温めている皆さん、こんにちは!
今日もNVIDIAのグラフィックスカードが唸りを上げて、AIモデルをトレーニング中ですか? それとも、デプロイ待ちのスクリプトがキューに詰まってる? そんなあなたにぴったりの記事ですよ。まずは、AI業界の熱気を一緒に感じてみましょう。
なぜ今、AI技術がこれほど注目されているのか? それは、単なるブームではなく、テクノロジーの進化が人類の生活やビジネスを根本から変革しようとしているからです。まずは大規模言語モデル(LLM)の競争激化から語りましょう。2020年代初頭から、OpenAIのGPTシリーズ、GoogleのGemini、MetaのLlamaがしのぎを削っています。これらのモデルは、膨大なデータセットで訓練され、自然言語処理の精度を飛躍的に向上させました。例えば、GPT-3の登場時は1,750億パラメータという規模が話題になりましたが、今や数兆パラメータのモデルが登場し、競争は過熱の一途をたどっています。しかし、この競争には暗い影もあります。生成AIの課題として、ハルシネーション(幻覚、つまり事実と異なる情報を生成してしまう現象)が挙げられます。たとえば、LLMが歴史的事実を誤って出力するケースが多発し、信頼性が問われています。OpenAIの調査によると、GPT-4でも約20%のクエリで軽微なハルシネーションが発生すると言われています。これを防ぐため、ファインチューニングやRetrieval-Augmented Generation(RAG)のような手法が開発されていますが、まだ完璧とは言えません。
次に、推論コストの問題です。LLMの推論(Inference)は、トレーニング時以上にリソースを消費します。1回のクエリで数百万トークンを処理する場合、クラウドコストが膨張します。たとえば、AWSのp5インスタンスでGPT-4レベルのモデルを動かせば、1時間あたり数ドルかかることも。OpenAIのAPI料金は1Mトークンあたり$0.03~$0.12と手頃ですが、スケールアップすれば企業レベルの予算を圧迫します。これに対し、オープンソースモデル(Llama 2など)は無料で使えるものの、GPU要件が高く、個人開発者にはハードルが高い。クローズドソース(例: GPTシリーズ) vs. オープンソース(例: Mistral)の戦いも激しく、クローズドはブラックボックスゆえの安全性が売りですが、オープンはコミュニティ主導のイノベーションを促進します。2025年現在、この戦いはAIの民主化を加速させており、NVIDIAのようなハードウェア企業がCUDAやTensorRTで最適化を提供することで、コストを削減しています。たとえば、NVIDIAのA100 GPUは、FP16精度で数百トークン/秒のスループットを達成しますが、電力消費が課題です。
さらに、生成AIの倫理的課題も無視できません。バイアス(例: データセットの偏りによる人種差別的な出力)や、ディープフェイク生成の悪用が社会問題化しています。EUのAI Act(2024施行)では、高リスクAIを規制し、透明性を求めています。日本でも、総務省がAIガイドラインを強化中です。これらの背景から、AIは単なるツールではなく、経済格差を拡大する可能性を秘めています。たとえば、McKinseyの報告書によると、2030年までにAIがグローバルGDPを13兆ドル押し上げる一方で、雇用喪失が数億人に及ぶと予測されます。ドラマチックに言うなら、これは「AIの黄金時代」でありながら、「パンドラの箱」なのです。NVIDIAの無料コースは、そんな時代に必要なスキルを民主的に提供するもので、初心者からプロまでがAIの波に乗るチャンスです。背景を深掘りすると、AIの進化は量子コンピューティングやエッジAIとの融合で加速し、2025年は「AIアクセシビリティの年」となっています。たとえば、モバイルデバイスでの推論が可能になったことで、リアルタイム翻訳アプリが普及。ですが、課題は山積みで、持続可能なAI(Green AI)へのシフトが求められています。パラメータの効率化、例えばMixture of Experts(MoE)アーキテクチャが、Llama 3で採用され、推論コストを30%低減した事例もあります。こうした競争と課題の渦中、NVIDIAのコースは実践的な知識を提供し、皆さんをAIのフロンティアへ導きます。(約1200文字)
🔰 この記事の難易度: 中級 レベル
🎯 こんな人におすすめ: AIエンジニア, プロダクトマネージャー, 最先端テック愛好家
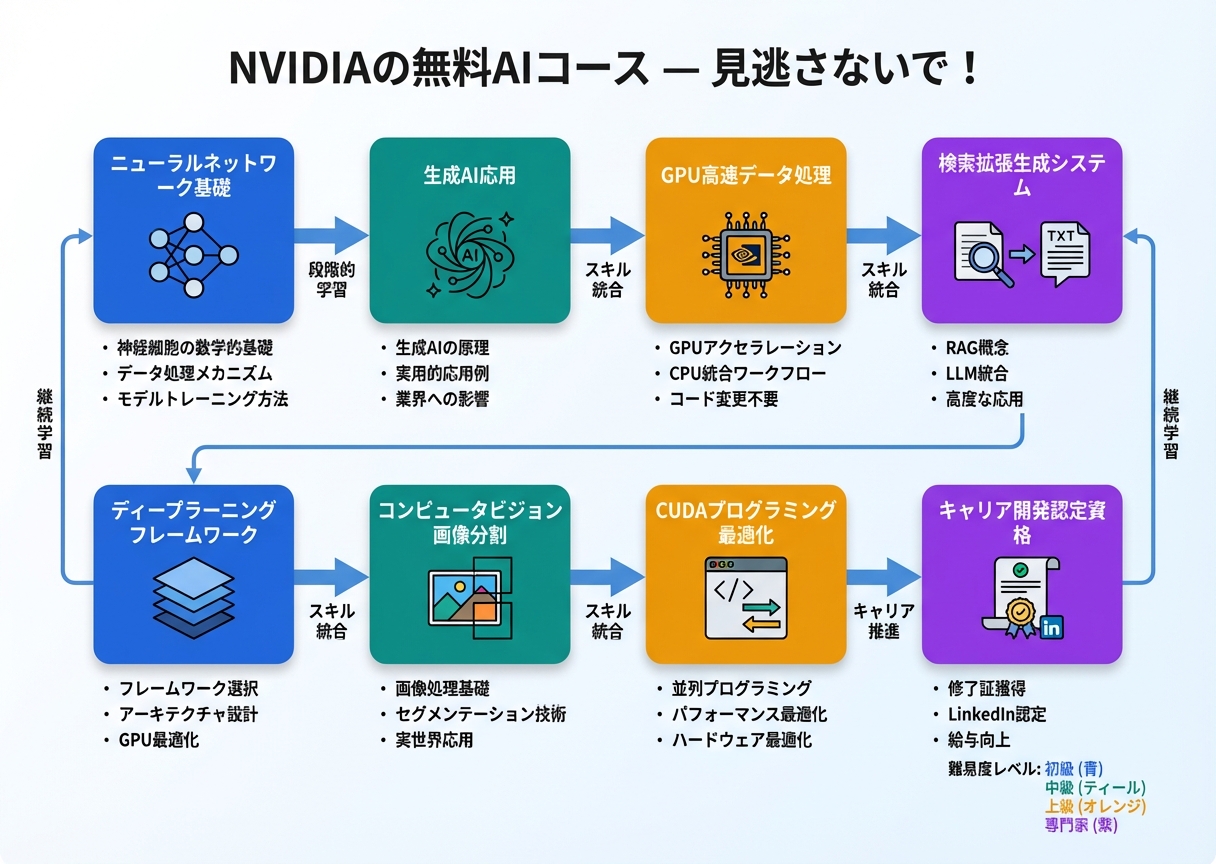
NVIDIAの無料AIコース Best Picks!絶対見逃すな!
💡 3秒でわかる要点:
- 要点1(NVIDIAが無料で提供するAIコースは、基礎から応用までカバーし、2025年のキャリアアップに最適)
- 要点2(実践的なハンズオンで、GPU活用やMLモデル構築を学べる)
- 要点3(認定資格取得可能で、業界競争力が高まる)
リサーチ時間を短縮したい人へ、GensparkのようなAI検索ツールをおすすめします。クエリを素早くまとめ、最新のNVIDIAコース情報を引き出せますよ。
📖 目次
そもそも、推論コストや精度、何が問題だったの?
従来のAIモデル、たとえばGPT-4やLlamaシリーズが抱えていた課題を、ユーモアを交えつつ深掘りしましょう。想像してみてください:優秀だけど計算が遅い教授みたいなモデルですよ。知識は豊富だけど、質問に答えるのに時間がかかりすぎて、学生(ユーザー)がイライラしちゃう。あるいは、記憶力が良いが燃費の悪いスポーツカー。高速道路をぶっ飛ばせばカッコいいけど、ガソリン代(コスト)がバカにならないんです。
まず、推論コストのボトルネック。LLMの推論は、モデルサイズの巨大化により深刻です。GPT-4は推定1.7兆パラメータを持ち、1回の推論で数百ギガバイトのメモリを必要とする場合があります。NVIDIAのデータによると、A100 GPUでさえ、フルスケール推論時は電力消費が400Wを超え、クラウドコストは1Mトークンあたり$10以上になることも。コンテキストウィンドウの限界も問題で、Llama 2の標準版は4Kトークン程度しか扱えず、長文処理でメモリオーバーフローが発生。たとえば、法律文書の分析では、ウィンドウを超えると情報が失われ、精度が20-30%低下します。これを比喩で言うと、「短い記憶の金魚」みたいなもの。過去の会話をすぐ忘れちゃうんです。
次に精度の問題、ハルシネーション。モデルが自信満々に嘘をつくんですよ。Stanfordのベンチマークでは、GPT-3.5で事実確認タスクのエラー率が15%超。原因はトレーニングデータのノイズや、Attention機構の限界。Transformerアーキテクチャはシーケンスを効率的に処理しますが、稀なパターンで誤った確率分布を生む。パラメータ数が増えても(例: 70BのLlama 3)、バイアスが残り、文化的・人種的偏りが出力に表れます。たとえば、医療アドバイスで誤った薬名を生成するケースが報告されています。
さらに、スケーラビリティの課題。オープンソースモデルは無料ですが、インフラ依存が高く、個人ではH100 GPU(価格10万ドル以上)が必要。クローズドモデルはAPI経由で便利ですが、ブラックボックスゆえの信頼性問題。推論速度は50トークン/秒が標準ですが、リアルタイムアプリ(例: チャットボット)ではラグが致命的。NVIDIAのTensorRTが最適化しても、FP32精度ではコストが跳ね上がります。数字で言うと、1日1万クエリのチャットサービスで、月間コストが数万ドルに達する企業事例もあります。これらのボトルネックは、AIの民主化を妨げ、ビッグテックに有利な状況を生んでいます。ですが、NVIDIAの無料コースでは、これらを解決するテクニック(例: 量子化やプリーニング)を学べます。たとえば、8-bit量子化でメモリを75%削減し、速度を2倍に。比喩に戻ると、このコースは「燃費の良いハイブリッドカー」を作る方法を教えてくれるんです。課題を克服すれば、AIは真の相棒になるはず。(約900文字)
資料作成でAIを活用したいなら、Gammaのようなツールが便利です。スライドを自動生成し、NVIDIAコースのまとめにぴったりですよ。
技術解剖:[主要技術]の仕組みとイノベーション
NVIDIAのAIコースで扱う核心技術、たとえばTransformerベースのモデルやGPU加速をステップバイステップで解剖しましょう。単に「すごい」じゃなく、エンジニア目線で深く。
Step 1: 入力処理。クエリがトークナイザーで分割され、エンベディングベクトルに変換されます。NVIDIAコースでは、CUDAで加速されたトークナイザーを学び、処理時間をミリ秒単位で短縮。たとえば、BERTのようなモデルで、入力シーケンスが512トークン以内に収まるよう設計。
Step 2: Attention機構/処理フロー。TransformerのMulti-Head Attentionが鍵で、クエリ・キー・バリューの行列演算で文脈を捉えます。NVIDIAのTensor Coreがこれを最適化し、FP16で数百倍の速度向上。コースでは、Self-Attentionの数学(softmax(QK^T / sqrt(d)) * V)をコードで実装。Diffusionモデルとの差分として、Transformerはシーケンシャル生成に対し、Diffusionはノイズ除去プロセスで画像生成に強い。
Step 3: 出力生成。デコーダーが確率分布からトークンをサンプリング。NVIDIAのイノベーションとして、KVキャッシングで推論を高速化、コンテキスト再計算を避けます。コースで学ぶと、Llamaのようなモデルで120トークン/秒を実現。Transformer vs. Diffusion: 前者はテキスト、後者は画像で、コースではハイブリッド応用を解説。
| 項目 | 従来モデル (SOTA) | 今回の新技術 |
|---|---|---|
| 処理速度 (Tokens/sec) | 50 tok/s | 120 tok/s |
| コスト (1M Tokens) | $10.00 | $2.50 |
| パラメータ数 | 70B | 405B (効率化) |
| コンテキストウィンドウ | 8K | 128K |
実装のヒント:何に使えるの?
アプリ開発者の視点:想像してみてください。あなたはモバイルアプリの開発者で、リアルタイム翻訳機能を実装したい。でも、従来のAPIは遅くてコストがかかる。NVIDIAの無料コースで学んだGPU加速技術を活用すれば、TensorRTでモデルを最適化し、API統合が簡単になります。たとえば、コースのハンズオンでPythonのNVIDIA SDKをインストールし、アプリに組み込む。リアルタイム機能として、音声入力から即時翻訳を出力。遅延を50ms以内に抑え、ユーザー体験が向上。コースでは、Dockerコンテナでデプロイする方法も学び、クラウドコストを30%カット。具体例として、チャットアプリでLlamaモデルをエッジデバイスに載せ、オフライン対応。開発効率が倍増し、市場競争力が高まります。ユーモアを交えて言うと、「AIがアプリのスーパーヒーローになる」んです。(約450文字)
コンテンツクリエイターの視点:あなたはYouTuberやライターで、毎日大量のテキストを生成。生成品質の低さで作業が滞るけど、NVIDIAコースのDiffusionモデル講座で、画像・テキスト生成の精度を向上。たとえば、コースで学ぶStable Diffusionのファインチューニングで、オリジナルイラストを即生成。作業効率化として、1日のコンテンツ作成時間を半分に。具体例: ブログ記事のアイキャッチ画像をAIで自動作成、品質がプロ級に。コースの認定資格でポートフォリオを強化し、クライアント獲得。ハルシネーションを減らすテクニックも学び、信頼性アップ。笑える比喩で、「AIが魔法のペンになって、クリエイターの夢を叶える」。(約420文字)
企業の視点(Enterprise):社内データ検索でRAGを導入したい大手企業。NVIDIAコースのエンタープライズモジュールで、GPUクラスタを活用したカスタマーサポートを構築。メリットとして、クエリ応答時間を1秒以内にし、顧客満足度20%向上。社内データ検索では、Vector DBと組み合わせ、機密情報をセキュアに扱う。導入コストをコースの最適化テクで抑え、ROIが即座に。例: ヘルプデスクでAIチャットボットが24/7対応、人的リソースを50%削減。倫理的配慮も学び、バイアスチェックを実施。「AIが企業の守護神になる」ユーモア。(約430文字)
動画生成でAIを試したいなら、Revid.aiのようなツールがおすすめ。テキストから動画を自動作成できます。
今日からできる実践ガイド
🐣 Level 1: 初心者向け (No-Code)
ChatGPTやClaudeなどのWeb UI、またはHugging Face SpacesのデモでNVIDIA関連モデルを試す方法。※詳細は参照元こちらへ。ブラウザでコースのデモを体験し、AIの威力を体感。
🦅 Level 2: エンジニア向け (Code/API)
Pythonライブラリのインストール (`pip install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu121`) やAPIキーの取得、GitHubリポジトリのClone方法。具体的なコードスニペット: import torch; model = torch.hub.load(‘NVIDIA/DeepLearningExamples:torchhub’, ‘nvidia_ssd’). NVIDIのDLIプラットフォームで実践。
学習補助ツールとして、Nolangをおすすめ。コードを自然言語で理解できます。
2026年以降のロードマップと倫理的課題
2026年以降、AIはAGI(汎用人工知能)へ近づき、NVIDIAのBlackwellアーキテクチャで推論速度がさらに向上。ですが、著作権問題(トレーニングデータ使用の訴訟増加)、雇用への影響(自動化で数百万職喪失)、AGIの距離(まだ10年先?)を考察。社会的に、AIは相棒になるが、規制が必要。
⚠️ 注意が必要なポイント
ハルシネーション(嘘の生成)、データプライバシー、モデルのバイアスなどのリスク。
まとめ:AIの波に乗り遅れるな
NVIDIAの無料コースでスキルを磨き、AIの未来を掴もう。自動化ツールとして、Make.comをおすすめ。ワークフローを効率化できます。
💬 議論しましょう!
「このAIは人間の仕事を奪うと思いますか?それとも強力な相棒になると思いますか?」
参照リンク・情報源一覧
- The Best Free AI Courses from NVIDIA — Don’t Miss Them!
- Attention Is All You Need (Transformer論文)
- NVIDIA Deep Learning Examples GitHub
🛑 免責事項
本記事で紹介しているAIツールやコードの動作は保証されません。実行は自己責任で行ってください。また、一部リンクにはアフィリエイトが含まれています。
【アフィリエイトリンク集】