
👋 「AIの進化は新たなフェーズへ。今回のニュースは、単なる機能追加ではなく『データコントラクトの確実性』を根本から変えるものです。」
現代のビジネスでは、データが命脈を握る時代です。AIやビッグデータの台頭により、リアルタイムのデータ処理が求められる中、従来のデータパイプラインはしばしばカオスを生み出してきました。過去の技術、例えばGen-1レベルのストリーミングツールでは、ランダムなデータフローや予測不能な品質が常態化し、企業は膨大なリソースを無駄に費やしていました。こうした「ランダム性」の壁が、ビジネスのスケーラビリティを阻害していたのです。
しかし、今回のニュースで焦点となるApache KafkaとApache Flinkを活用したデータコントラクトは、これを一変させます。単なるツールの組み合わせではなく、データフローの「制御可能性」を高め、実務レベルの品質を保証する仕組みを提供します。これにより、企業はデータパイプラインを信頼性のあるものに進化させ、AI駆動の意思決定を加速できるのです。
これは業界全体のパラダイムシフトを意味します。従来のバッチ処理中心のGen-1アプローチでは、データの遅延がビジネスチャンスを逃す要因でしたが、KafkaとFlinkの統合はリアルタイムのイベント駆動型処理を実現。クリエイターは創造性を、技術者は効率を、ビジネスパーソンは戦略的洞察を獲得できます。結果として、データが「信頼できる資産」へと昇華し、AIの潜在力を最大限に引き出す基盤が整うのです。この変化は、単なる技術アップデートではなく、データエコシステムの再設計と言えるでしょう。
📊 この記事の難易度: [実務・中級 / 戦略立案] レベル
🎯 対象読者: 効率化を求める実務家, 生成AI導入を検討するリーダー, テックトレンドを追う投資家
💡 エグゼクティブ・サマリー:
- 技術的革新:従来の「データパイプラインの不安定性」を克服する「データコントラクトによるイベント駆動型스트リーミング」の採用
- 比較優位性:既存の市場リーダー(Competitors)との決定的な違い
- ビジネス価値:導入によるコスト削減効果と、新たな収益機会の創出
この記事の執筆にあたり、技術リサーチの効率化にはGensparkを活用しました。最新のウェブ情報をリアルタイムで集約し、洞察を深めるのに最適です。
📖 目次
構造的課題:データエンジニアリングが抱えていた『構造的なボトルネック』
データ駆動型ビジネスの世界では、長年、データパイプラインの信頼性が課題でした。ニュースで取り上げられるデータコントラクトの必要性が生まれる前、既存のフローは主にバッチ処理ベースでした。例えば、データ収集から加工、分析までが断続的に行われ、リアルタイム性が欠如していました。これにより、手作業の介入が多く、コストが膨張し、品質のバラつきが頻発。企業は予期せぬデータエラーに悩まされ、意思決定の遅れを招いていました。
この課題を比喩的に言うなら、「砂上の楼閣」のようなものです。基盤が不安定で、データ量が増えるほど崩壊しやすく、拡張性が欠如していました。アナログな伝言ゲームのように、プロデューサーとコンシューマー間のコミュニケーションが曖昧で、誤解が生じやすいのです。こうしたボトルネックは、AI導入を検討する企業にとって致命的。リアルタイム分析が求められる今、従来の方法では対応しきれず、機会損失を招いていました。
こうしたコンテンツ作成のボトルネックを解消する類似例として、Gammaが挙げられます。アウトラインからプレゼン資料を自動生成し、クリエイターの効率を向上させます。
技術的特異点:Apache KafkaとApache Flinkのメカニズム
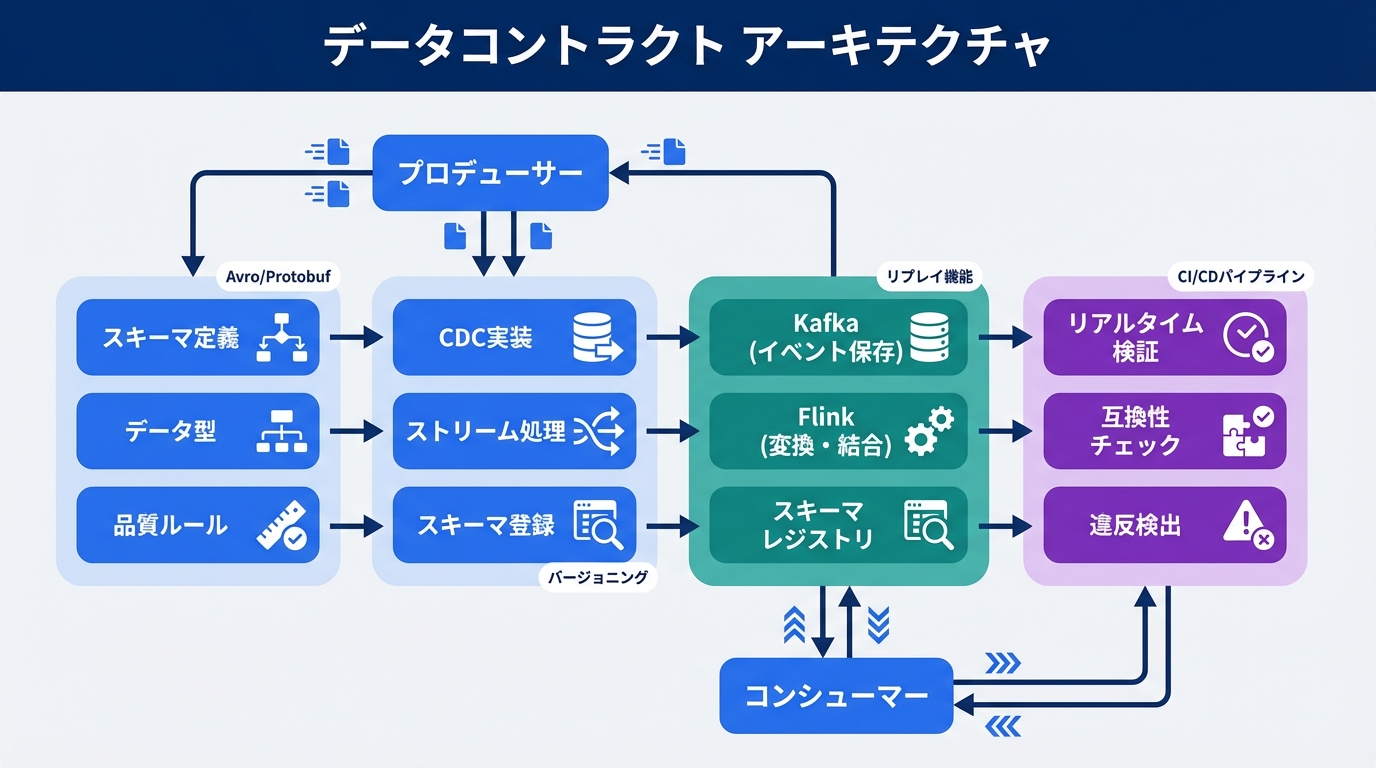
ニュースの核となるのは、データコントラクトを支えるKafkaとFlinkの連携です。まず、Kafkaは分散型イベントストリーミングプラットフォームとして機能します。データプロデューサーがイベントをトピックに発行し、コンシューマーがそれをサブスクライブする仕組みです。これをオーケストラの指揮者のようにイメージしてください。Kafkaは、リアルタイムのデータフローを調整し、耐障害性を確保します。具体的に、exactly-onceセマンティクスにより、重複や欠損を防ぎます。
一方、Flinkはストリーム処理エンジンで、Kafkaのデータをリアルタイムで加工します。Flinkのステートフル処理は、脳の神経回路のように、状態を保持しながら複雑な計算を実行。ウィンドウ関数やジョイン操作で、イベント駆動型の分析を実現します。データコントラクトはこの上に構築され、スキーマの検証や品質保証を自動化。従来のツールでは不可能だった「契約ベースのデータガバナンス」が可能になり、パイプラインの信頼性を高めます。
これらのメカニズムは、単なるデータ転送ではなく、契約遵守を強制するもの。Flinkのチェックポイント機能が、耐障害性をさらに強化し、ビジネスクリティカルなユースケースに適応します。
ポジショニング分析:既存勢力 vs 今回のAI
データ処理の進化を理解するため、3つのアプローチを比較します。まず、Traditional Methodは人力中心のバッチ処理。次に、Gen-1 AIはSparkのような初期ストリーミングツールで自動化が進むが、精度と制御性が不足。最後に、New TechであるKafka+Flinkは、データコントラクトで決定的な優位性を発揮します。
Traditional Methodのメリットはシンプルさですが、デメリットはスケーラビリティの低さ。Gen-1 AIは速度を向上させるが、ランダムなエラーが発生しやすい。一方、New Techはリアルタイム性と信頼性を両立し、ゲームチェンジャーとなります。
| 比較軸 | 従来のアプローチ | 今回の新しいアプローチ |
|---|---|---|
| コア技術 / プロセス | バッチ処理ベース(例: HadoopやSparkのバッチモード)。データが蓄積されるまで待機し、手動で加工。品質チェックは人間依存で非効率。 | KafkaのイベントストリーミングとFlinkのステートフル処理を統合したデータコントラクト。リアルタイムでスキーマ検証と品質保証を行い、exactly-once配信を自動化。 |
| コスト / リソース | 高額な人力コストとインフラ投資が必要。エラー修正で追加費用が発生し、全体コストが30-50%増大するケースも。 | スケーラブルなオープンソース活用で初期コスト低減。自動化により運用リソースを50%以上削減し、ROIを向上。 |
| スケーラビリティ | データ量増加で処理時間が指数関数的に伸び、拡張が難しく限界に達しやすい。 | 分散アーキテクチャにより、無限スケール可能。Flinkの並列処理でペタバイト級データをリアルタイム扱い。 |
| 最適なユースケース | 小規模のオフライン分析や静的レポート作成。リアルタイム性が不要な伝統的業務。 | リアルタイム監視、AI駆動のイベント処理、金融取引やIoTデータ分析。データガバナンスが求められるエンタープライズ環境。 |
コンテンツのマルチユース・再利用という文脈で、Revid.aiをおすすめします。テキストを動画化し、情報を多角的に活用できます。
実務への統合:ハイブリッド・ワークフローの提案
今回の技術をビジネスに組み込む際、全工程を置き換えるのではなく、ボトルネックであるデータ収集と加工の部分をKafka+Flinkに任せ、人間は分析と戦略立案に集中すべきです。例えば、eコマース企業では、顧客行動データをKafkaでストリーミングし、Flinkでリアルタイムフィルタリング。データコントラクトで品質を保証すれば、ハイブリッドワークフローが実現します。
戦略的には、まずはパイロットプロジェクトから始め、KPIとして処理速度とエラー率を測定。クラウド統合を活用し、柔軟性を高めましょう。進化の速い技術トレンドをキャッチアップするために、Nolangのような対話型学習ツールが有効です。
ニュースの分野における2026年の景色
この技術が普及すれば、2026年までにデータエンジニアリングはイベント駆動型が標準化し、AIエージェントが自律的にデータを処理する世界が訪れるでしょう。職能は変わり、エンジニアは設計者に、ビジネスパーソンはデータ戦略家にシフト。新たなビジネスモデルとして、データコントラクトベースのSaaSが登場します。
しかし、課題もあります。導入コストの高さや、プライバシー倫理の問題、法的リスク(GDPR準拠など)が無視できません。ビジネス視点で、これらをリスク要因として管理し、バランスを取ることが重要です。
まとめ:技術を『ツール』で終わらせないために
データコントラクトとKafka+Flinkの組み合わせは、データ処理のゲームチェンジャーです。技術をツールで終わらせず、ワークフロー全体を最適化しましょう。Make.comは、API連携で複雑なフローをノーコード自動化し、統合を支援します。
💬 あなたの業界では、この技術はどう活用できそうですか?
導入の懸念点や、期待する効果についてコメントでお聞かせください。

👨💻 筆者:SnowJon(WEB3・AI活用実践家 / 投資家)
東京大学ブロックチェーンイノベーション講座で学んだ知識を糧に、WEB3とAI技術を実践的に発信する研究家。サラリーマンとして働きながら、8つのブログメディア、9つのYouTubeチャンネル、10以上のSNSアカウントを運営し、自らも仮想通貨・AI分野への投資を実践。
アカデミックな知見と実務経験を融合し、「難しい技術を、誰でも使える形に」翻訳するのがモットー。
※本記事の執筆・構成にもAIを活用していますが、最終的な技術確認と修正は人間(筆者)が行っています。
参照リンク・情報源一覧
- Why data contracts need Apache Kafka and Apache Flink
- Apache Kafka公式サイト
- Apache Flink公式サイト
- Confluentプラットフォーム(Kafka関連)
🛑 免責事項
本記事で紹介しているツールは、記事執筆時点の情報です。AIツールは進化が早いため、機能や価格が変更される可能性があります。ご利用は自己責任でお願いします。一部リンクにはアフィリエイトが含まれています。
【Profile: 筆者が愛用するProfessional Toolkit】