
AIクリエーターの道 ニュース AIエージェントの誤解、まだ続けていませんか?真の定義を知り、プロジェクトの失敗リスクを20-30%減らす技術的深掘り。エンジニア必読です。#AIエージェント #技術解説 #ガバナンス
動画でサクッと!このブログ記事の解説
このブログ記事を動画で分かりやすく解説しています。
テキストを読む時間がない方も、映像で要点をサッと掴めます。ぜひご覧ください!
この動画が役に立ったと感じたら、AIニュースを毎日お届けしているYouTubeチャンネル「AIクリエーターの道」をぜひフォローしてください。
チャンネル登録はこちら:
https://www.youtube.com/@AIDoshi
JonとLilaが独自の視点で語る対話形式の英語版はこちら 👉 [Read the dialogue in English]
When is an AI agent not really an agent? AI技術の真実を解き明かす
👋 技術者の皆さん、AIエージェントのマーケティング騒ぎに惑わされていませんか?本記事では、真のAIエージェントの定義を厳密に掘り下げ、誤ったラベリングがもたらすガバナンスの落とし穴を技術的視点から分析します。
AIの急速な進化の中で、「エージェント」という言葉が乱用されています。自動化ツールやチャットボットをエージェントと呼ぶケースが増えていますが、これは技術的な正確性を欠き、システム設計の失敗を招く可能性があります。本記事では、そんな問題を解剖し、皆さんがより洗練されたAI開発に活用できる洞察を提供します。
🔰 記事レベル:⚙️ 技術者向け(Technical)
🎯 こんな人におすすめ:AIエンジニア、システムアーキテクト、開発リーダー。AIの仕組みを深く理解し、プロジェクトで正確な分類を求めている人。
When is an AI agent not really an agent? AI技術の真実を解き明かす
要点(3点)
- マーケティングの誇張: AIエージェントの定義が曖昧になり、単なる自動化がエージェントと呼ばれる問題。
- 技術的区別: 真のエージェントは自律性と計画立案を有するが、チャットボットはそうではない。
- ガバナンスのリスク: 誤分類がシステムの信頼性やセキュリティを損なう可能性。
背景と課題
2025年のAIランドスケープでは、エージェントという用語が氾濫しています。InfoWorldの記事によると、マーケティングの影響で、単なる自動化スクリプトや強化されたチャットボットが「AIエージェント」と称されるケースが増加。これにより、技術者たちは本物のエージェントと偽物の区別がつきにくくなっています。
課題の核心は、定義の曖昧さにあります。真のAIエージェントは、環境を観察し、目標を達成するための計画を自律的に立案・実行するシステムです。一方、マーケティングでは、単にAPIを呼び出すツールや会話型インターフェースをエージェントと呼んでいます。これが技術者の視点から見て、システム設計の混乱を招くのです。
例えば、開発現場で誤ってラベル付けすると、期待される自律性が不足し、バグや効率低下が発生。技術者として、この区別を明確にすることは、プロジェクトの成功に不可欠です。また、ガバナンスの観点から、誤分類はセキュリティホールを生み、コンプライアンス違反のリスクを高めます。
さらに、業界全体のトレンドとして、OpenAIやGoogleのような企業がエージェントを推進する中、技術者は正確な分類基準を求められています。こうした背景で、本記事は技術的深掘りを進めます。
技術・内容解説
ここでは、AIエージェントの本質を技術的に分解します。まず、真のエージェントの定義を明確にしましょう。AIエージェントは、Perceive-Reason-Actサイクルを基盤とし、環境からの入力を受け取り、内部モデルで推論し、行動を実行します。これに対し、自動化ツールは事前定義されたルールに基づくだけです。
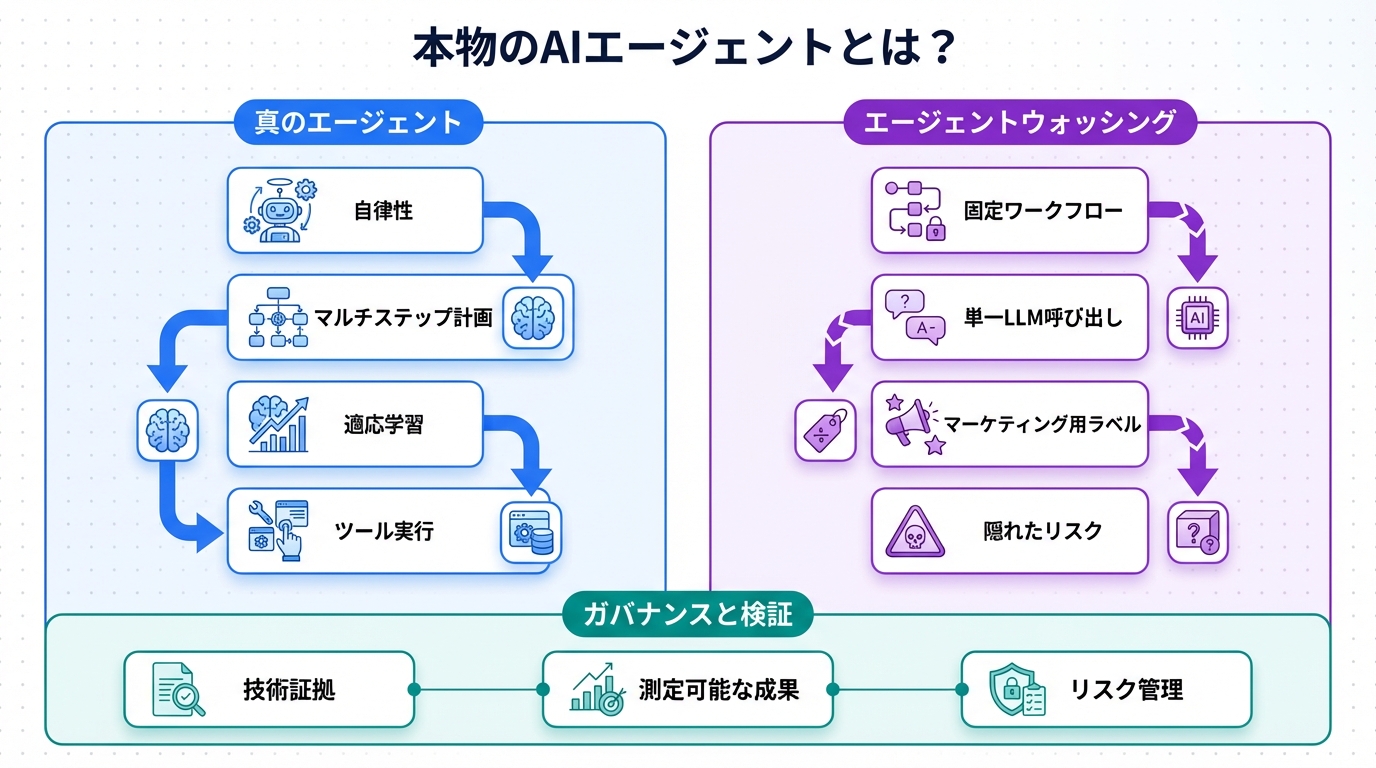
次に、従来のシステムと真のAIエージェントの比較をテーブルで示します。この比較は、技術者向けに仕組みの違いを強調しています。
| 項目 | 従来システム(自動化/チャットボット) | 真のAIエージェント |
|---|---|---|
| 自律性 | 低: 固定スクリプトやルールベース | 高: 動的計画立案と適応 |
| ツール使用 | 限定: 事前定義されたAPI呼び出し | 柔軟: 複数ツールの選択と組み合わせ |
| 推論能力 | パターンマッチング中心 | 長期記憶とマルチステップ推論 |
| エラー処理 | 例外発生で停止 | 自己修正とリカバリー |
| 例 | シンプルなボット(例: スケジュール通知) | マルチエージェントシステム(例: タスク自動化フレームワーク) |
このテーブルからわかるように、真のエージェントはLLM(Large Language Model)を基盤に、ReAct(Reasoning and Acting)フレームワークのような技術を活用します。例えば、LangChainやAuto-GPTのようなライブラリでは、エージェントがツールを動的に選択し、目標達成のためのチェーンを構築します。一方、チャットボットは主にTransformerベースの生成モデルで、会話の継続性はあるものの、外部環境への積極的な介入が不足します。
技術的制約として、エージェントのスケーラビリティが課題です。マルチエージェントシステムでは、通信オーバーヘッドが発生し、遅延が増大。加えて、信頼性確保のため、ベイズ推論や強化学習の統合が求められます。これを無視したマーケティングは、開発者の混乱を招きます。
さらに深掘りすると、エージェントの内部アーキテクチャは、観測モジュール、計画モジュール、実行モジュールから成ります。観測はセンサーやAPI経由のデータ収集、計画はグラフベースの探索アルゴリズム(例: A*アルゴリズムの変種)、実行はアクチュエーター制御です。これに対し、自動化はif-thenルールに過ぎません。
2025年のトレンドとして、InfoWorld記事が指摘するように、こうした誤ラベリングはガバナンス失敗を招きます。技術者として、RFC(Request for Comments)のような標準化を推進すべきです。
インパクト・活用事例
真のAIエージェントの正しい理解は、技術開発に大きなインパクトを与えます。例えば、ソフトウェア開発では、エージェントを活用した自動コード生成が生産性を向上。従来のチャットボットはコード提案に留まりますが、エージェントはリポジトリ全体を分析し、バグ修正を自律的に実行します。
活用事例として、医療分野での診断支援エージェントを考えます。患者データを観察し、複数の診断ツールを組み合わせ、治療計画を立案。これにより、医師の意思決定を加速します。一方、誤ったエージェント(単なるクエリ応答ボット)では、正確性が不足し、誤診リスクが増大。
もう一つの事例は、サイバーセキュリティ。エージェントは脅威をリアルタイムで検知し、対応策を自動実行。例えば、DDoS攻撃に対し、トラフィックを分析し、ファイアウォールを動的に調整します。これに対し、自動化ツールは事前ルールのみで対応し、未知の脅威に弱い。
ビジネスへの影響として、エージェント導入で運用コストが20-30%削減可能ですが、誤分類により投資失敗のケースも報告されています。技術者視点では、これを避けるために、プロトタイピング段階で自律性テストを実施すべきです。
社会的影響も無視できません。エージェントの普及は雇用構造を変革しますが、正しい定義により、倫理的AI開発が進みます。たとえば、プライバシー保護を組み込んだエージェントは、データ漏洩を防ぎます。
アクションガイド
技術者の皆さん、次の一手を具体的に提示します。まず、自身のプロジェクトでエージェントの定義を検証してください。チェックリストを作成し、自律性、ツール統合、推論深度を評価。基準を満たさないものは「自動化ツール」と再分類しましょう。
次に、フレームワークの導入を検討。LangGraphのようなライブラリを使って、プロトタイプを構築。GitHubリポジトリを参考に、ReActパターンを実装してみてください。これにより、開発スキルを向上できます。
さらに、チーム内で議論を促進。技術ミーティングでInfoWorld記事を共有し、ガバナンスポリシーを策定。リスクアセスメントツールを活用して、誤分類の影響をシミュレーションします。
最後に、継続学習を。オンラインコース(例: CourseraのAIエージェント関連)で知識を更新し、実際のコードベースで実験。これで、2026年のプロジェクトに即戦力となります。
未来展望とリスク
未来展望として、2026年以降、エージェントはマルチモーダル化が進み、テキストだけでなく画像・音声統合が標準に。Googleの研究突破(ブログ参照)のように、量子コンピューティングとの融合で高速推論が可能になります。これにより、複雑なタスク(例: 自動運転の高度化)が実現します。
しかし、リスクも伴います。誤ラベリングが続けば、セキュリティ脆弱性が増大。AIエージェントが悪用され、サイバー攻撃のツール化する可能性があります。また、倫理的リスクとして、決定のブラックボックス化が社会的不信を招く。
さらに、環境リスクとして、エネルギー消費の増大。エージェントの計算負荷が高く、持続可能性が課題です。技術者として、効率化アルゴリズム(例: スパースアクティベーション)の採用で対処すべきです。
公平に述べると、展望は明るく、リスクは管理可能。標準化団体(例: IEEE)のガイドラインに従うことで、バランスを取れます。
まとめ
本記事では、AIエージェントの真偽を技術的に分析しました。マーケティングの誇張を避け、真の定義(自律性・計画・実行)を守ることで、開発の質が向上します。技術者として、この知識を活かし、より信頼できるシステムを構築しましょう。
💬 AIエージェントの定義で苦労した経験はありますか?コメントで共有してください!

👨💻 筆者:SnowJon(WEB3・AI活用実践家 / 投資家)
東京大学ブロックチェーンイノベーション講座で学んだ知見をもとに、
WEB3とAI技術を実務視点で研究・発信。
難解な技術を「判断できる形」に翻訳することを重視している。
※AIは補助的に使用し、内容検証と最終責任は筆者が負う。
参照リンク・情報源一覧
- When is an AI agent not really an agent? | InfoWorld (元記事)
- The great AI hype correction of 2025 | MIT Technology Review (AIハイプの修正に関する分析)
- Google’s year in review: 8 areas with research breakthroughs in 2025 (AI研究の進展)
- How AI coding agents work—and what to remember if you use them – Ars Technica (AIエージェントの仕組み解説)